ビッグデータ分析のシステムと開発がしっかりわかる教科書

ビッグデータ分析の全体像
システムの全体像
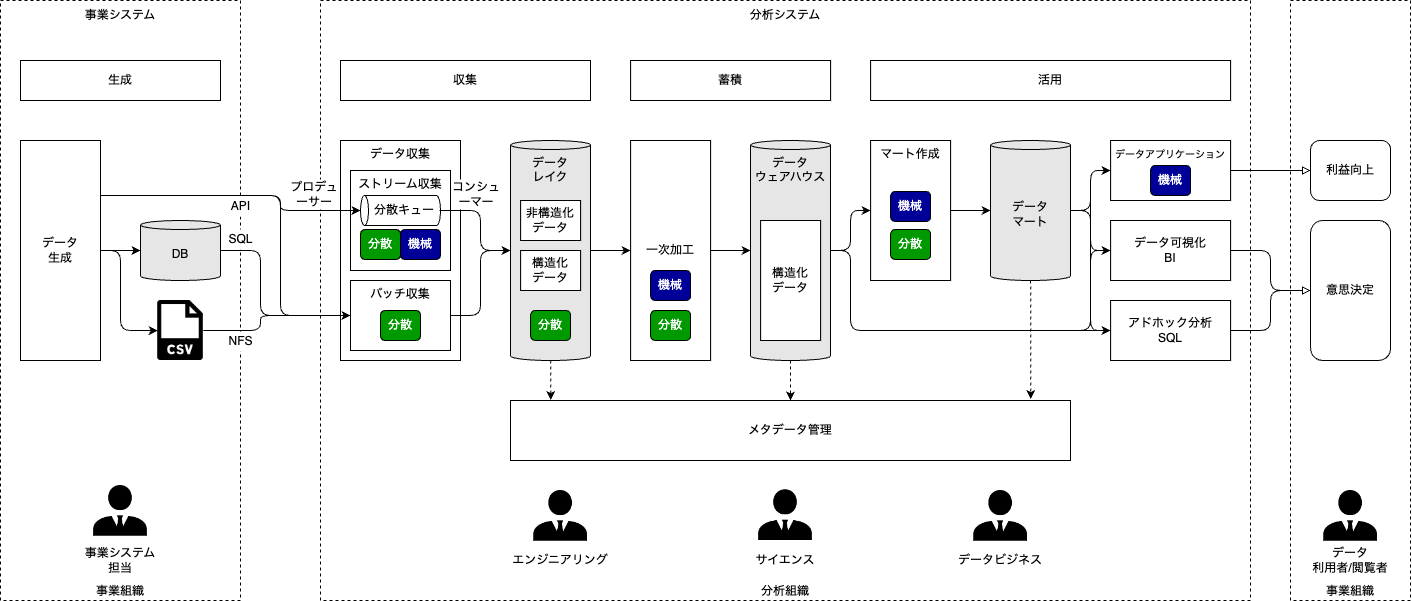
- 事業システム … 高い可用性が求められるミッションクリティカルなシステム
- 分析システム … 高い可用性は求められないが、分析をスピーディーに試せる高い開発生産性が求められる
関係者と役割
- 事業組織 … 利益を上げている組織
- 分析組織 … ビッグデータ分析システムを担当する組織
| 人 | 役割 |
|---|---|
| 事業システム担当 *事業のシステムに詳しい人 |
事業システムでデータを生成する。 |
| エンジニアリング *分析システムを支える人 |
分析システム全体の設計・開発・運用をする。 メタデータ管理も行う。 |
| サイエンス *分析技術に詳しい人 |
データから知見を取り出す方法を実装し、日々改善する。 特徴を数値化し、機械学習で類似度を計算したりする。 一度開発したモデルが陳腐化していないか監視する。 |
| データビジネス *分析データに詳しい人 |
データ分析により企業の利益を上げる。 事業担当者が決めた目標(事業の急所として設定されたKPI)を 達成するシステム・分析要件への落とし込みを行う。 |
| データ利用者 *事業に詳しい人 |
SQLでデータを分析して意思決定する。 |
| データ閲覧者 *事業に詳しい人 |
可視化されたデータを見て意思決定する。 |
エンジニアリングの希少価値
エンジニアリング力がないと、データ分析による継続的な利益向上を維持できない。
本番システム化に必須な存在
本番システム化は一回限りの実証実験とは異なり、考慮すべき点が大きく変わる。
- 継続的なデータの収集法
- 分析精度の監視
- 分析結果を利益に結びるける箇所の自動化
- 処理が業務時間内に間に合うか
- ソースコード・リリースの管理
希少性
最初からビッグデータエンジニアリングをできる人はほとんどいない。 Webシステムや基幹業務システムでインフラ構築・運用経験のある人を採用し、経験を積んでもらうことが現実的な解。
活用段階
活用段階の低い企業が、多額の投資でデータアプリケーションをいきなり作ることは現実的ではない。 スモールスタートでシステムを作り、成果を積み上げて徐々に進化させていく。
| 段階 | 名前 | 企業の状態 |
|---|---|---|
| 1 | アドホック分析 | データをSQLで不定期に分析し、意思決定を行う |
| 2 | データ可視化 | ダッシュボードでデータを可視化し、一般社員も意思決定を行う - データを見る文化の醸造 - BI製品の利用 |
| 3 | 分析自動化 | データの収集から可視化までがシステム化されている - ジョブコントローラー(流れの制御)が必要 - エンジニアリング力が不可欠 |
| 4 | データアプリケーション | 分析結果を利用したアプリケーションが運用されている 例: カスタマーの行動に応じた広告を出す |
ビッグデータの収集
収集方法
- ストリームデータ収集 … データが生成されたら即時に収集する
- バッチデータ収集 … 定期的にデータを収集する
| 観点 | ストリーム | バッチ |
|---|---|---|
| 処理タイミング | 随時 | 定期的 |
| データ鮮度 | ◯ 新しい | ✗ 古い |
| 漏れのない収集 | ✗ 難しい | ◯ 可能 |
| 構築・運用の難易度 | ✗ 難しい | ◯ 易しい |
| 更新されるデータの収集 | ✗ 難しい | ◯ 可能 |
| 処理の負荷 | ◯ 均等 | ✗ 偏る |
データ構造変更対応
ビジネスの変化でデータ構造・量が変化するため、データ収集は分析システムの中でもっとも運用が大変。 決まったデータ構造にしか対応していないと、構造が変わったときに処理そのものが失敗してしまう。
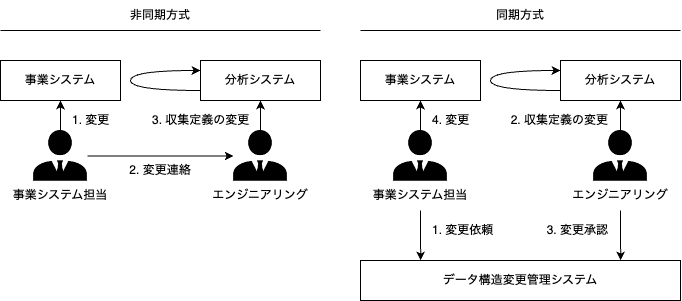
非同期方式と同期方式
企業内のデータ分析の優先度に応じて決まる。
バッチ収集 対象ファイル
ファイルフォーマットの種類
csv
zipやgzipに圧縮して扱う。 データ型を定義できない。
json
階層型のデータを扱う場合に適している。 データ型を定義できない。
avro
avroはバイナリデータファイルで、独自のバイナリフォーマットでデータ量を小さくし、高速に処理できる。
avscはavroのデータ構造定義ファイルで、階層型のデータも扱える。
ファイル収集のトリガー
事業システムでトリガファイル(ファイルの配置完了を示す)を作成する。トリガファイルがあれば収集する。
バッチ収集 対象DB
SQLによる収集
SELECT文のカーソルを発行し、少しずつフィッチして収集する。 データはローカルにファイルとして保存し、そのファイルをデータレイクに格納する。
加工しつつ収集
SQLで匿名化加工などを行いつつ収集できる。
並列に収集
収集対象テーブルを何かしらのキーで分割し、複数の収集ワーカーで同時に収集できる。
データベース負荷に注意
SQLによる収集は、事業システムのデータベースに最も負荷をかける。以下の点に注意する。
- データベースのキャッシュ洗い流し(アクセスの少ない時間帯に収集する)
- コネクション数溢れ
- 長時間トランザクション(一般的に障害扱いされてしまう)
データ出力による収集
データベースのテーブルを出力し、それをファイルとして収集する。 データベースの負荷が低いことがメリット。 ただし、整合性を保ったダンプかどうかに注意。
更新ログ同期による収集
更新ログを取得して元のデータベースの複製を作る。一般的に「準同期レプリケーション」という。 環境構築が難しく運用も大変なため、事業データの負荷低減を最優先する場合のみ検討する。
バッチ収集 対象システム
APIによる収集
データ構造が変わっても収集処理が失敗しないように、jsonをそのままデータレイクに格納することが重要。
スクレイピングによる収集
Webサイトの担当者と連絡が取れない場合、User-Agentに自身の連絡先を記載する。
バッチ収集 ツール
バッチデータ収集を行うツールは、ETL(Extract Transform Load)と呼ばれる。
製品ETL Embulk
コネクタがオープンソースのプラグインで、誰でも開発できる。 豊富なコネクタで、ほとんどのデータソースと接続できる。
自作ETL
既存のETL製品は複雑すぎるため、半数以上は自作している。
ストリーム収集
生成されるデータを受け止めて一時的に保持しておくために分散キューを用いる。 分散キューは難しい特性が多く、運用が想像以上に難しい。
ストリーム収集 ツール
オープンソース
- Apache Kafka … ビッグデータのストリームデータ収集のために作られたミドルウェア
マネージドサービス
- AWS Kinesis Data Streams … 分散キューのマネージドサービス
- AWS Simple Queue Service … 小さなデータ(システム間の命令)を伝達するためのサービス
自作コンシューマー
分散キューのデータをデータレイクに入れるだけであれば、自前のプログラム(無限ループで分散キューのデータを処理する)でもよい。 AWS LambdaやGCP Cloud Functionsなどを利用すれば、分散キューにメッセージが入ったことをトリガにでき、常駐プログラム化が不要になる。
データレイク
収集した生データをファイル(構造化データ: csv, 非構造化データ: 画像, テキスト, 音声)としてすべて溜めておく。 どんな形式のファイルも格納でき、データ量に応じてスケールアウトできる分散ストレージが最適。
分散ストレージ
単純に、8個のディスクの付いたコンピュータを10台用意すれば、80個のディスクから同時に読み出せる。
HDFS (Hadoop Distributed File System) アーキテクチャ
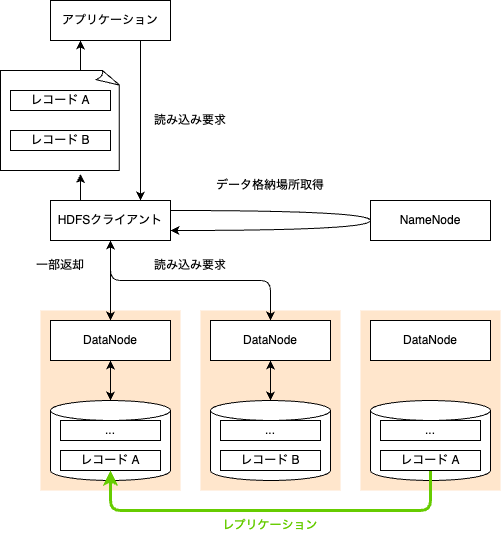
- レプリケーション
可用性を高めるために、1つのデータを複数のコンピュータに複製保持する - リードレプリカ
読み取り用にデータを複製し、読み取りのスループットを上げる方式
クラウド オブジェクトストレージ
分散ストレージの一種。 データを分散して格納し、データにアクセスできるエンドポイントを提供する。
結果整合性
分散ストレージへの変更が、すぐに見えるとは限らない。 ストレージ間での状態共有にラグが生じる。
ビッグデータの蓄積
一次加工
データレイクのデータを加工し、データウェアハウスに格納する。
| 処理 | 補足 |
|---|---|
| バリデーション | データ構造・型が想定通りか |
| 非構造化データの構造化 | 機械学習等を用いる |
| クレンジング | 欠損値埋め、異常値削除、制御文字削除、フォーマット修正 |
| 名寄せ処理 | 「高」と「髙」を同じ文字として扱う |
| 結合処理 | トランザクションデータとマスターデータを結合して分析で使いやすくする |
| 機密情報の除去 | 個人情報のマスク処理 |
| 表形式データへの変換 |
データウェアハウス
データベース製品には2種類(データ操作が得意なオペレーショナルDBとデータ分析が得意なアナリティックDB)あるが、 DWHにはアナリティックDBを使う。
DWHはデータレイクよりも容量あたりの費用が高価であるため、DWHにすべてのデータを入れることは現実的ではない。
DWHにはアドホック分析用にSQLインターフェイスや個人作業用データスペースを準備する。 利用者にリソースを使いつくされないためにリソース制限をかける。
アナリティックDB
データを一括ロードしたあと、データ全体に集計をかけるような処理を得意とする。 応答速度よりもスループットに重点を置く。
列指向
列方向にデータを固めて保持する。データ全体のスキャンが不要なため、特定列への集計は高速になる。 ある行の更新・削除は、その行を含む全ての列指向データの書き換えが必要になるため、非常に低速になる。
符号化による圧縮
「列方向に類似したデータが並ぶ」という特性から、データを符号化により圧縮できる。 為替レートの例では、平均値の値とその差分だけを格納する。
アナリティックDB ツール
- SQL on Hadoop
- DWH製品
- オンプレミス: Teradata
- クラウド: AWS Redshift, GCP BigQuery, Snowflake
BigQuery
データは、GCSからBigQueryにロードして利用することが一般的。
Redshiftは事前にリソースを確保するため、常に固定のコストがかかる。 BigQueryはクエリ毎の課金であり、この点が大きく異なる。 大企業では部門ごとにクエリの費用を負担しつつデータは共有するケースが多い。
Snowflake
BigQueryと類似した機能をAWSやAzureで実現できる。
オペレーショナルDB
少量データへのランダムなデータ操作が得意。 処理の応答速度を重視し、一回のクエリであれば数ミリ秒から数十ミリ秒で処理する。
行指向
行へのアクセスが高速になるように作られている。
オペレーショナルDB ツール
- リレーショナルデータベース
- オンプレミス: MySQL, SQL Server
- クラウド: AWS Aurora
- NoSQLデータベース
- オンプレミス: MongoDB
- クラウド: AWS DynamoDB
アナリティックDBとオペレーショナルDBの比較
| 観点 | アナリティックDB | オペレーショナルDB |
|---|---|---|
| 得意な処理 | データの抽出・集計 | データの細かい操作 |
| データの持ち方 | 列指向 | 行指向 |
| 重要視する性能 | スループット | 応答速度 |
| 更新・削除 | △ できないor遅い | ◯ できる |
| トランザクション | ✗ できない | ◯ RDBはできる |
| データの集計 | ◯ 速い | ✗ 遅い |
| データのロード | ◯ 速い | ✗ 遅い |
ビッグデータの活用
データマート
計算リソースの最適利用と汎用的な集計の統一のため、データ可視化やデータアプリケーション用にDWHのデータを加工する。
データマート作成
SQLを利用する
ただしSQLで完結する場合に限る
SQLに加えてUDF(ユーザ定義関数)を合わせて利用する
SQLには用意されていない関数を実現したい場合に用いる。BigQueryであればJSで書ける。
外部で計算する
UDFで利用できない外部ライブラリを利用する場合に用いる(GPUを利用した機械学習など)。 最近では、BigQuery MLのようにSQLの文法のみで機械学習が実現できたりする。
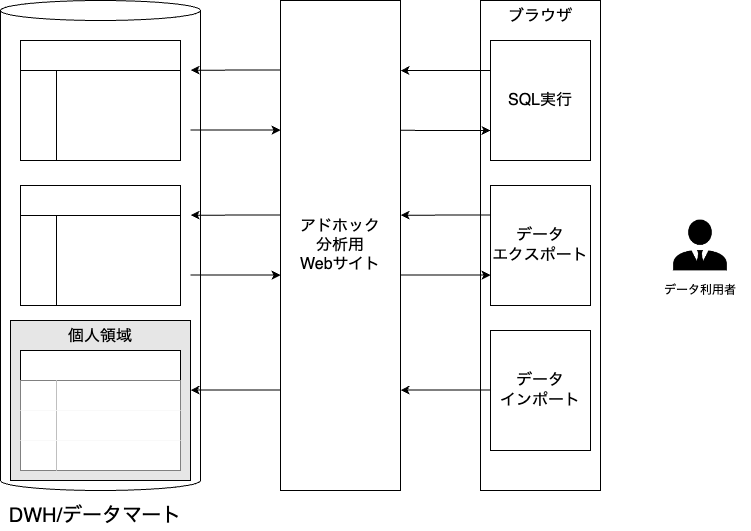
アドホック分析
優秀なデータサイエンティスト1人よりも、データで意思決定できる社員100人のほうが企業には有益。
誰でも使えるユーザインターフェース
アドホック分析の普及には、ユーザインターフェースやメタデータの開示が重要。 データの意味(メタデータ)を簡単に知ることのできるドキュメントやポータルが必要。
データ利用者サポート
- 一般的なシステムユーザ管理プロセス
- 問い合わせ対応窓口の準備
- 障害発生時の通知手段
その他のデータ活用
データ可視化
「意思決定が行われる」までが責任範囲。使われていないレポートは定期的に改善・廃棄する。
データアプリケーション
利益に結び付く部分まで責任を持つ。分析システムの一部としてデータアプリケーションも管理する。
メタデータ管理
メタデータ管理はデータマネジメントの一貫。興味がある人は、DMKBOK(Data Management Body of Knowledge)を読んでみるとよい。
メタデータ一覧
| 分類 | メタデータ | 説明 | 利用用途 |
|---|---|---|---|
| 静的 | データ構造 | 名前や型 | 障害予防、分析作業効率向上 |
| 静的 | データ辞書 | ビジネス上の意味 | 分析作業効率向上 |
| 静的 | データオーナ | 生成・管理者 | 分析作業効率向上 |
| 静的 | データリネージ | どこから来てどこに行くか | 障害影響調査、分析作業効率向上 |
| 静的 | データセキュリティ | 誰に参照権限があるか | 情報漏洩防止 |
| 動的 | データ鮮度 | いつのデータか | 質の悪いデータ除去 |
| 動的 | データ完全性 | 不正に変更されていないか | 質の悪いデータ除去 |
| 動的 | データ統計値 | 性質が変わっていないか | 障害予防、分析作業効率向上 |
| 動的 | データ利用頻度 | どれくらい利用されているか | 整理・棚卸し |
データオーナ
データの意味がわからない場合に、データオーナに聞きに行く。
データリネージ
管理できていないと、問題・障害発生時の影響調査に苦労する。
データ鮮度
いわゆる createdAt と updatedAt のこと。
埋め込み方式(データに鮮度列を追加)と外部管理方式(データ鮮度管理システム)がある。
データ統計値
「単調増加していたテーブルが増えなくなった」等、データ収集の動作状況を把握できる。
メタデータ管理 製品
多くの場合、自前でメタデータ管理システムを作成している。 今後は製品(GCP Data Catalog等)が拡大されてくると考えられる。
データカタログ
データ構造とデータ辞書のまとめサイト。データ利用者が使用する。 構造や辞書の編集機能(編集リクエストやレビュー機能)も備える。
データカタログ責任者
データカタログを正しい状態で維持するため、事業組織にデータカタログ責任者を置く。
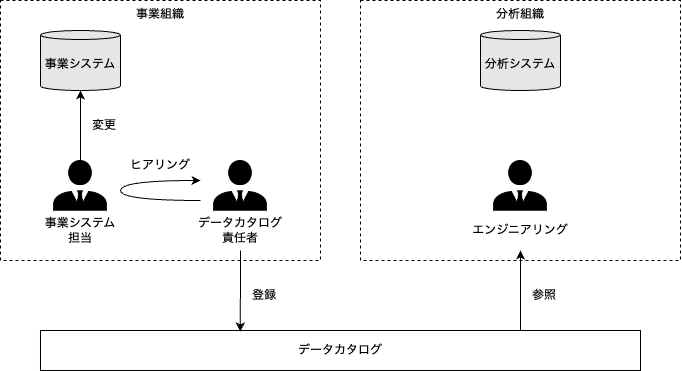
データカタログとデータ構造変更管理システム
同一システムに同居させてもよいが、要件が異なることに注意する。
データリネージ管理システム
データ処理の入力と出力を管理する。多くの場合、自前でシステムを作成している。
分散処理
リソースマネージャ
クラスター(複数コンピュータのまとまり)のリソースを管理し、分散処理を割り当てる役割を担う。
性能問題
ビックデータ分析で起こる問題のほとんどに性能が関係している。
ボトルネック
「ボトルネック」を解析し、解消する。 システムのボトルネックとは、処理時間の中で「その部分が早くなれば全体の処理時間が短くなる部分」のこと。
ボトルネックの発生箇所は移り変わっていく。 ボトルネックを解消し続け、業務要件に見合う処理速度になったときに、性能問題は解消できたことになる。
ディスクボトルネック
ディスクのボトルネックがもっとも多い。
プロセッサボトルネック
プロセッサの使用率監視をするときは、コアごとに行うことが鉄則。
ネットワークボトルネック
ネットワークの全体像(図)がつかめれば、ボトルネックを特定できる。
特に、オンプレとクラウドを結ぶ通信は物理的に離れていることが多く、 大きな帯域幅を維持することが難しいため、ボトルネックになりがち。
ボトルネック以外
メモリ枯渇
メモリのスワップアウトが発生していないか確認する。
非効率処理
リソースに余裕がある場合には、処理が非効率であることが考えられる。
分散計算
ビッグデータ分析で重要なことは、やろうとしている計算が分散できるかを常に考えること。 コーディネータが複数の計算ノードに計算を指示し、結果をまとめてプログラムに返す。

SQLの分散計算
HadoopプロジェクトのHiveが最も有名。HiveはSQLをMapReduceの関数に書き換えて分散計算する。 記述が難しすぎるため、MapReduceが直に使われることはほとんどない。
分散処理 ツール
Hadoop
HadoopプロジェクトはApacheソフトウェア財団のプロジェクトの1つで、分散処理をするためのさまざまなソフトウェアの総称。
Hadoopの欠点は、「ソフトウェアが重厚長大で運用が大変である」こと。 数十台規模では採算が合わず、クラウドでこと足りるため、Hadoopはあまり使われなくなってきている。
クラウド
Hadoopの利用と自前の分散処理はそれなりに手間であり、クラウドの利用がもっともラク。
- マネージドETLサービス(データの抽出・変換・挿入)
- AWS Glue
- GCP Data Fusion
- データウェアハウスサービス
- AWS Redshift
- GCP BigQuery
機械学習
機械学習の種類
| 種類 | 説明 |
|---|---|
| 教師あり機械学習 回帰 | 過去データで未来データの数値予測 |
| 教師あり機械学習 分類 | 過去データでデータの分類予測 |
| 教師なし機械学習 | データの規則性や類似性を導き、データの特徴付けや分類付けを行う |
| 強化学習 | 機械の判断にフィードバック(報酬)を与える |
教師あり機械学習
1次関数とディープニューラルネットワーク
1次関数を用いた回帰を「重回帰分析」といい、ビジネスの現場でもよく使われる。
1次関数とディープニューラルネットワークは、機械学習にとって同じ役割を果たす。 しかし、計算の複雑さは全く異なる。

工程
前処理・特徴量抽出
データの特徴を表す数値を「特徴量」という。 特徴をうまく表現するデータに変換することが必要になる。
訓練データ・検証データ・テストデータの用意
推定したモデルは検証データを予測するように作られるため、検証データとは別にテストデータを用意する。 機械学習では準備が非常に大変で、「データサイエンティストの仕事の8割が準備」と言われることもある。
モデル推定
訓練データと検証データでモデルを推定し、テストデータで評価する。 評価結果から特徴量やモデルの改善を繰り返し、モデルの精度を高めていく。 このプロセスを「学習」という。
ハイパーパラメータチューニング
モデル自体のパラメータ以外の要因を「ハイパーパラメータ」といい、学習する回数やアルゴリズムなどが該当する。 さまざまなハイパーパラメータを試すことを「ハイパーパラメータチューニング」という。
本番リリースとABテスト
ABテストでは、現行モデルと新モデルを同時に運用し、挙動の影響を比較する。
エンハンス
劣化してきたモデルの精度をもとに戻すこと。 初期構築したデータサイエンティストにエンハンスの方法を引き継いでもらうことを徹底する。
機械学習 ツール
Python
- NumPy … 数値計算ライブラリ
- Pandas … データの前処理や特徴量エンジニアリングに最適
Jupyter Notebook
予測精度を表すグラフをプログラムと共に成果物として管理できる。