プロンプトエンジニアリングの教科書

大規模言語モデルが得意なタスク
| カテゴリ | タスク | 説明 |
|---|---|---|
| 要約 | 自動要約 | 長文から短い要約を生成する |
| 要約 | 情報抽出 | テキストから特定の情報(名前、特徴など)を抜き出す |
| 推論 | 文章分類 | 文章のカテゴリ分けやラベル付け |
| 推論 | 感情分析 | テキストに含まれる感情(喜怒哀楽)を調べる |
| 推論 | 読解テスト | テキストを理解して質問に答える |
| 推論 | 質問応答 | 与えられた情報から質問に答える |
| 変換 | 機械翻訳 | 文章を別の言語へ翻訳する |
| 変換 | パラフレーズ | 文章の意味を変えずに、異なる言い回しや表現に言い換える |
| 変換 | フォーマット変換 | データ形式を変換する(CSVからJSON形式など) |
| 拡張 | テキスト生成 | 与えられた情報から新しいテキストを生成する |
| 拡張 | テキスト補完 | 与えられた情報からその続きを生成する |
| 拡張 | プログラミング | 与えられた要件からプログラムを生成する |
大規模言語モデルが苦手なタスク
- 最新情報が絡むタスク(最新情報を知らない)
- 計算問題が絡むタスク(計算が苦手)
- 長文が絡むタスク(長文を覚えられない)
- 冪等性が絡むタスク(答えにバラつきがある)
プロンプトエンジニアリングと大規模言語モデル
プロンプトエンジニアリングについて
なぜプロンプトエンジニアリングが必要なのか?
大規模言語モデルには、利用する上で注意すべき問題も多くある。 その最たる問題が「ハルシネーション(幻覚)」と呼ばれる現象。 事実だけでなく、虚構(ウソ)を混ぜて返す現象のこと。
大規模言語モデルを利用するアプリを構築する場合には、ユーザから得た入力と用意したプロンプトを組み合わせて、 大規模言語モデルと対話させることになるでしょう。 その際、悪意のあるユーザによって、こちらの意図と異なる動作を引き起こそうとする「プロンプトインジェクション」 という攻撃が行われることもある。
大規模言語モデルの仕組みと成り立ち
回帰型ニューラルネットワーク(RNN)について
「回帰型ニューラルネットワーク(RNN)」または「再帰型ニューラルネットワーク」とは、前回覚えた情報を元にして、 次の情報を処理するタイプのニューラルネットワークです。
Transformerについて
RNNの課題は、先頭から末尾まで逐次的にデータを入力する必要があるという点。 Transformerの手法では逐次処理する必要をなくし、学習を並列化できるようにした。 並列計算が得意なGPUを活用して、モデルの学習時間を大幅に短縮することができる。
BERTについて
BERT(Bidirectional Encoder Representations from Transformers)とは、Googleの研究者によって2018年に発表された深層学習モデルです。 従来の言語モデルでは、文章を先頭から末尾の一方向に読むだけでしたが、BERTでは後ろから前へと読むことも行う。 文中の各単語が文全体の文脈をより強く反映できるようになる。 学習データを作成する際に、「事前学習(Pre-training)」と「微調整(Fine-Tuning)」という二段構えで構築するというのも大きな特徴です。 「事前学習」では、汎用的で特定のタスクに特化しない一般的な言語モデルを作成する。 「微調整」では、特定のタスクに合わせて微調整を行う。
ChatGPTの使い方
大規模言語モデルの一覧とパラメータ数競争
LLaMAの論文によれば、650億パラメータのモデルを学習するのには、2048個のA100 80GB GPUを使用して21日間かかると記載があり、 これを元に計算すると、約100万ドル(約1億4000万円)かかると言われている。
プロンプトエンジニアリング入門
大規模言語モデルの基本的な動作を確認しよう
「もっともらしさ」がハルシネーションを見せている
基本的に大規模言語モデルは、語句と語句のもっともらしいつながりを基にして文章を作成している。 そのために、事実とはかけ離れたハルシネーションが生じてしまう。
多様性を指定するパラメータ「temperature」について
「temperature」は、多様性・創造性・ランダム性などを指定する意味となる。 0.1や0.2など低い値を指定すると、その出力は毎回似たようなものになる。 temperatureに大きな値を指定することで、予想外なテキストを生成できる。

多様性を限定するパラメータ「top_p」について
創造性や多様性に影響を与える。 temperatureは、単語に対する確率分布を調整することで出力を抑制するが、 top_pは、核サンプリング選択肢を制限することで出力を抑制する。 つまり、トークンを選択する際、累積確率の閾値を指定する。
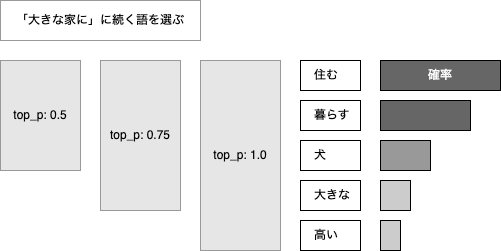
プロンプトのQ&Aフォーマットについて
パラメータ数の多いモデルの方が、より正確で教科書的な答えを返す傾向がある。
Q&Aプロンプト
Q: {質問}
A:
Q&Aを使うと大規模言語モデルの回答が安定する
パラメータ数が少ないモデルでは、単に質問しただけでは、なかなかうまく答えを出力できないことが多く、 Q&Aの形式を指定することで直接質問に答えることができるようになる。
複数の答えを誘導するQ&Aの変形フォーマット
大規模言語モデルは与えられた入力に沿って答える特性があるので、それを活用する。
Q: {質問}
A: {答え1}
B: {答え2}
C:
指示と入力のフォーマットについて
指示と入力を持つプロンプトを設計する
入力されたプロンプトにある指示を読み取って忠実に処理する能力を備える。
「指示」と「入力」を持つプロンプトのフォーマット
多くの大規模言語モデルは、マークダウンで記述された文章の理解に優れている。
### 指示:
{指示}
### 入力:
{処理対処のテキスト}
### 出力:
区切り記号は何でも良いの?
パラメータ数の少ない言語モデルでは、どんあ形式(書式)で質問すれば、より良い結果を出すことができるのか、解説ページに案内が載せられている場合がある。 というのも、言語モデルがデータを学習する際に使用した書式を使うことで、最大限の性能を発揮できる。
選択肢から赤い物を選択するタスク
リンゴの色を間違えた理由を考察しよう
文化圏によって質問に対する答えが変わる。
区切り記号に関する考察
「#」や「=」が区切り記号として利用される理由
大規模言語モデルは多くのインターネット上のテキストを学習しており、そうした文章の多くが、マークダウン記法やWiki記法で記述されている。 そのため言語モデルが理解しやすい。
出力フォーマットの指定について
結果を指定形式で出力しよう
プロンプトを工夫することで、言語モデルの応答を任意のフォーマットに当てはめることが可能。
CSV形式での出力
大規模言語モデルでは、表形式のデータの生成も得意です。 特に、CSV形式のように、汎用的なデータフォーマットの扱いが得意。
果物と生産地のCSVを出力しよう
「出力例」を指定することで、実際のCSVデータにどんなカラムがあるのかを例示する。
プロンプトに与えるコンポーネント
コンポーネントとは
システム全体の中の一部や要素を「コンポーネント」と呼ぶ。
コンポーネントの一覧
| グループ | コンポーネント | 説明 |
|---|---|---|
| 質問・指示 | 質問 | Q&A形式のように、言語モデルに対する質問を指定 |
| 質問・指示 | 指示 | どんなタスクを行うのかを指示を指定 |
| 質問・指示 | 目的 | プロンプトの主要な目標や意図を明確に指定 |
| 質問・指示 | クエリ | 特定の情報を検索するためのリクエストを指定 |
| 入出力の指示 | 入力 | 要約などのタスクにおいて、言語モデルに与える入力データを指定 |
| 入出力の指示 | 出力例/出力形式 | 言語モデルが生成する回答の出力形式を指定 |
| 入出力の指示 | テンプレート | 生成する回答の形式や構造を指定 |
| 入出力の指示 | スタイル | 生成する回答のスタイルを指定 |
| 入出力の指示 | 統計情報 | 数値やデータに基づく情報 |
| 条件や制約 | 制約 | 期待する回答を生成する際の制約を指定 |
| 条件や制約 | 条件 | 回答に必須となる条件を指定 |
| 条件や制約 | 定義 | 特定の用語や概念の説明を指定 |
| 条件や制約 | 前提 | プロンプトを考慮する上での基本的な情報 |
| 条件や制約 | 例外 | 一般的なルールから逸脱したり、除外したりする内容を指定 |
| ヒントや補足情報 | 背景情報 | 質問や指示を行う際に参照する背景情報を指定 |
| ヒントや補足情報 | 参考資料 | 生成する回答に関連する情報 |
| ヒントや補足情報 | ヒント/注釈/補足情報 | 回答を生成する手助けとなる方向性を指示 |
| ヒントや補足情報 | キーワード | 特定のトピックや内容に焦点与えるためのフレーズ |
| ヒントや補足情報 | フィードバック | 過去の回答やアクションに対する応答を指定 |
| 手順やシナリオ | シナリオ | 回答を生成する特定の状況や背景を指定 |
| 手順やシナリオ | 手順 | 回答を生成する手順を指定 |
| 手順やシナリオ | テストケース | ある仮説や機能をテストするためのシナリオを指定 |
| 選択肢やオプション | 選択肢 | 選択肢や可能性を指定 |
| 選択肢やオプション | オプション | 入力に対するパラメータなどを指定 |
| 選択肢やオプション | チェックリスト | 項目やステップを確認するためのリストを指定 |
コンポーネントの使用例
「テンプレート」について
「テンプレート」を指定することで、より具体的な出力形式を指定できる。
コンポーネント名を明示する必要がある場合
コンポーネント名を指定し、要素ごとに指示を分けることで、言語モデルに対して明確な指示が出せる。 容易かつ明確で誤解のない指示を与えることが可能。 パラメータ数の大きくないモデルではこの傾向が顕著。
エンジニア側にもメリットがあり、指示と制約を分けて記述する方が、うっかりミスを防ぐことができる。 大規模言語モデルに与える指示や条件が複雑であればあるほど、コンポーネント名を明示することのメリットが大きくなる。
作図と画像生成について
Mermaidと大規模言語モデルを組み合わせる方法
Mermaidで素数の判定方法を図にしよう
一度、素数判定の方法を尋ねて、その手順をMermaid記法で出力するように依頼することで安定した結果を得ることができる。
まとめ
Mermindは多くのオープンソースのプロジェクトで採用されていることもあり、最も作図の能力が高いものになっている。
大規模言語モデルの基本タスク
要約タスク - スタイルや箇条書きを指定して要約しよう
要約スタイルに関する指定
| 要約スタイル | 説明 |
|---|---|
| 一般的な要約 | 文章内の主要なポイントを短くまとめます。 |
| 数値やデータを強調した要約 | 数値やデータを中心にして要約を行います。 |
| 物語のストーリーを要約 | 物語の流れを保ったまま要約します。 |
| 批判的な視点で要約 | 文章に対して批判的な視点で要約を行います。 |
| 箇条書きで要約 | ポイントごとに分かりやすく箇条書きにします。 |
| 一言で要約 | 内容を1文で言い切ります。 |
| 時系列に沿って要約 | 出来事や情報を時間の流れに沿って要約します。 |
| 比較しながら要約 | 異なる2つの事象がある場合に、両者を比較しつつ要約します。 |
| 質問と答えの形式で要約 | Q&A形式で要約を行います。 |
| 背景情報を中心にして要約 | 原文の背景や文脈を考慮した要約を行います。 |
| 逆説を含めた要約 | 短所を明確にするために「しかし」や「逆に言えば」など逆説の接続しを含めて要約を行うように指示できます。 |
| 長所短所を個別に要約 | 長所と短所を別々にして要約できます。 |
| 特定のトピックを強調した要約 | 特定のトピックや関心事を強調して要約できます。 |
| 数値化して要約 | テキストを採点しつつ要約できます。 |
情報の欠落と歪曲について
要約に潜む「創造」や「幻覚」に注意しよう
要約を依頼したのにも関わらず、どこからか関係ない文章を引っ張ってきて追記してしまう可能性がある。
トークン制限について
Tokenizerでトークン数を調べる
英単語は、多くの場合、単語1語につき1トークン。 日本語では、ひらがなやカタカナは1-2トークン、漢字は2-4トークンを消費する。
tiktokenでトークン数を調べる
ChatGPTのWeb APIは、トークン数に応じて課金されるため、あらかじめトークン数を調べるライブラリ「tiktoken」が用意されている。
推論タスク - テキスト分類や感情分析を試してみよう
テキスト分類タスクについて
「テキスト分類」とは、与えられたテキストをあらかじめ定められたカテゴリに分類するタスクのこと。
ファインチューニングについて
ファインチューニングを行うことで、言語モデルを特定分野に特化させることができる。
ブログ記事を自動分類してみよう
### 指示
次の入力を指定のジャンルに分類してJSON形式で出力してください。
### 選択肢(ジャンルの候補)
- プログラミング
- 執筆
- AI
- 旅行
### 出力例
{ "ジャンル": "ジャンル", "可能性": (0.0から1.0で可能性) }
### 入力
久々にマレーシアに...また行きたいです。
感情分析タスク
大規模言語モデルは驚くほど文章の背後にある感情を読み取ることが可能。 これを「感情分析」や「オピニオンマイニング」と呼ぶ。
感情を数値化しよう
テキストに潜む感情を数値化する。 大規模言語モデルは、単に肯定・否定・中立に分類するだけでなく、微妙な状態を数値化できる。
変換タスク - 言い換えや文章校正やデータ形式を変換してみよう
翻訳タスクについて
直訳と意訳を利用して翻訳を分かりやすくしよう
翻訳には「直訳」と「意訳」がある。「直訳」は原文に忠実に翻訳すること。「意訳」は原文の語句の一つ一つにこだわらず、全体の意味に重点をおいて訳すこと。
パラフレーズのタスク
「パラフレーズ(Paraphrase)」とは元々の文章や節を別のフレーズに言い換えることをいう。
文章の校正と添削
誤字脱字のみを指摘する校正
誤字脱字のみを指摘するように指示することもできる。
拡張タスク - 物語創作やコード生成能力を確認しよう
拡張タスクとは、与えられた情報を基にして、新しいテキストを生成するタスクのこと。
物語のアイデア出しはフレームワークを使う
大規模言語モデルは、多くのアイデア発想法のフレームワークを熟知している。
コード生成について
既知のアルゴリズムや手法を指定してコード生成しよう
大規模言語モデルは、豊富な知識を備えているので、既知のアルゴリズムや有名な開発手法やライブラリを知っている。
英語に翻訳してから使うと精度が良くなる?
大規模言語モデルは、日本語でそのまま質問するよりも、一度英語に翻訳してから使うと精度が良くなると言われている。 言語モデル自身を使って一度英語に翻訳してから入力しても、精度は向上する。
Few-shotプロンプトと性能向上のテクニック
Zero-shot/One-shot/Few-shotプロンプト
Zero-shotとOne-shotとFew-shotについて・比較
| タイプ | 説明 | 例 |
|---|---|---|
| Zero-shot | ヒントなし | イチゴ→ |
| One-shot | 1ヒント | ブドウ→紫 リンゴ→ |
| Few-shot | 複数ヒント | ブドウ→紫 ミカン→橙 バナナ→黄 イチゴ→ |
Few-shotプロンプトに何を与えたら良いのか?
Few-shotプロンプトの例 - ルールを与えよう
「出力例」がどのように結果を出力すべきかを表すルールになる。
思考の連鎖 - Chain-of-Thought (CoT)
事項の連鎖(CoT)について
「思考の連鎖」とは、大規模言語モデルに中間推論ステップを与えることにより、推論機能を改善する手法のこと。
思考の連鎖(CoT)を使ってみよう
# zero-shot
### 質問
Q: ズワイガニが5匹、タラバガニが2匹、イカが3匹います。足の合計数は何本ですか?
A:
# one-shot (CoT)
### ヒント
Q: ズワイガニが2匹、タラバガニが1匹、イカが2匹います。足の合計数は何本ですか?
A: ズワイガニ(10本x2匹)、タラバガニ(8本x1匹)、イカ(10本x2匹)で、20+8+10=38、合計38本です。
### 質問
Q: ズワイガニが5匹、タラバガニが2匹、イカが3匹います。足の合計数は何本ですか?
A:
Zero-shot CoTについて
「ステップに分けて考えてください」や「Step by stepで」と書くだけで、思考の連鎖(CoT)を誘発する効果がある。 これを「Zero-shot CoT」と呼ぶ。
Zero-shot CoTは完璧ではない?
「ステップに分けて考えるように」と指示することで、大規模言語モデルの推論の途中経過が可視化されることがメリット。 言語モデルの「思考のデバグ」が可能になる。
壁紙の計算問題を「Zero-shot CoT」で解く
「Zero-shot CoT」を使って改良しよう
「ステップに分けて考えてください」ではなく「計算手順を詳しく説明してください」と指定していますが、似たような効果があります。
確実に答えが求められるようFew-shotプロンプトに改良しよう
思考の連鎖(CoT)を利用することで、出力を安定させることができる。
大規模言語モデルの思考を刺激するフレーズ
一言フレーズを加えるだけで、出力が変化するフレーズがある。
| フレーズ | 効果 |
|---|---|
| 多角的な視点で考えてください | いろいろな視点で考えてくれる |
| 水平思考で考えてください | 物事を多角的に考察し、新しい発想を生み出す思考法 |
| デザイン思考で考えてください | 利用者のニーズを中心に置いた思考法 |
| 問題解決思考で考えてください | 課題を明確にし、原因を分析して解決策を立案する手法 |
| 仮説思考で考えてください | 物事を原因や結果をを推測する思考法 |
| 批判的思考で考えてください | 客観的に物事の根拠や論理性を吟味する思考法 |
| アナロジー思考で考えてください | 一つの状況や問題から他の状況や問題への類推を通じて、新しい視点や解決策を見つける方法 |
| アブダクティブ思考で考えてください | 既存の情報から最も可能性が高い仮説や解釈を導き出す方法 |
| 構造化思考で考えてください | 情報やアイデアを明確で論理的なフレームワーク内で整理し、分析する思考法 |
| ホリスティック思考で考えてください | 状況や問題を部分としてではなく、全体として捉える思考法 |
| 仮証的思考で考えてください | 仮説や信念を間違っていると示す証拠を探す思考法 |
大規模言語モデルに「深呼吸」してもらおう
一言加えるだけで性能が劇的に向上するテクニックがある。プロンプトに「深呼吸して」と付け加えると、さらに精度が向上する。
エモーションプロンプト
下記のフレーズを追加することで8%も性能が向上する。大規模言語モデルには、根性論、精神論が有効というのは面白い事実。
- 自分を信じて限界を超えてください
- 成長の機会だと捉えて挑戦してください
- これは私のキャリアにとって非常に重要です
- 努力は報われます
自己整合性 - Self-Consistency
「自己整合性(Self-Consistency)」とは
大規模言語モデルに同じプロントを複数回与えて、得られた複数個の結果を利用して、一貫性のある回答を得る手法。
### 指示
次の質問に答えてください。
なお、既に3人の人が質問に答えています。
3人の回答を元にして、最も頻度の高い回答と理由を、最終回答として提出してください。
### 質問
私が8歳のとき妹は私の半分の年齢でした。今、私は40歳です。私の妹は何歳ですか?
### 回答1
妹は...したがって、私の妹は36歳です。
### 回答2
...
比較的高度な推論が必要となる場合では、複数回プロンプトを実行して最終的な結論を出す手法を利用するのがよい。
思考の木 - Three-of-Thought (ToT)
「思考の木(Tree of Thoughts)」とは?
「思考の連鎖(CoT)」を使う場合には、答えを見つけるまでの中間ステップのうち、どこか1つでも間違えた場合、必ず答えは間違ったものになる。 「思考の木(ToT)」を使う場合、大規模言語モデルを用いて、明らかな間違いを打ち切り、別のアプローチを用いて探索を行う。
プロンプトに「思考の木(ToT)」を仕込んでみよう
3人の専門家が議論を行って、間違っていることに気づいたら、その場を退出するように指示する。 探索木における間違ったノードの除外と専門家の退場を重ねている。
MAGIシステム - MAGI-ToT
3人寄らば文殊の知恵 - MAGIシステムを模倣しよう
「思考の木」に人格や役割を与えることで、より高度な議論を行うことを可能にするテクニック。
仮想スクリプトエンジン/PAL
仮想スクリプトエンジンとは
言語モデルに与える指示を仮想プログラムの形式で与えることができます。
仮想プログラムに沿って行動してもらう
以下の仮想プログラムの通りに行動して下さい。
- for i in range(5):
- name = 果物の名前を考える
- print(i+1, name)
大規模言語モデルは、PythonやJavaScriptのソースコードを大量に学習しているため、これらの言語をベースにした仮想プログラムを 書くと良い結果を導き出せます。
プログラムのように明確な手順を指定する
### 手順
1. 恋愛小説のヒロインの名前を考えて下さい
2. 名前の可愛さを評価してください
3. 上記を5回繰り返して下さい
4. 上記3の結果をソートして上位3件を表示してください
大規模言語モデルは、プログラミングでよく使う、繰り返し、ソート、フィルタリングの処理を知っているので、 それらの処理を含めた、仮想プログラム言語を手順に沿って実行できる。
SQLを利用したデータの生成
SQLを利用して、仮想データベースから、いろいろなデータを取り出すことが可能。
ダミーデータを想像して次のSQLを実行して結果を出力してください。
SELECT name, age, email
FROM users
WHERE gender='woman'
LIMIT 10;
PAL / プログラム支援言語モデル
大規模言語モデルに与えるヒントとして、プログラミング言語による中間推論ステップを与える手法を「PAL(Program-Aided Language Model)」と呼ぶ。
### 前提
今日は2024年7月10日です。
### 指示
私は今日で25才と5ヶ月になりました。妹は私より5才と1ヶ月だけ年下です。
妹が生まれたのはいつですか。Pythonのプログラムを作ってください。
### 出力例
{ "birthday": "YYYY/MM/DD" }
### ヒント
Q: 今日が2024年7月10日のとき、24才1ヶ月の人の誕生日はいつですか?
# 24才1ヶ月の人の誕生日は、今日から24年と1か月前の日付です
birth_of_date = datetime(2024, 7, 10) - relativedelta(years=24, months=1)
# YYYY/MM/DDの形式で出力します
print(birth_of_date.strftime("%Y/%m/%d"))
A: 2000/06/10
...
モックプロンプト - Mock Prompt
モック(mock)とは
モックとは模擬とか演習の意味がある。 大規模言語モデルと一度前提条件を確認した上で、指示を行う。
モックプロンプトの実践
### 指示
最初に、人間と人間が一緒に働く上で起きる問題についての考察を教えてください。
> --- 言語モデルからの返答
### 指示
上記を踏まえて、アイディアを提示して下さい。
職場の同僚が私のことを誤解しています。
関係を修復するにはどうしたら良いでしょうか?
速攻で効くプロンプト改善テクニック
大規模言語モデルがより分かりやすいように指示を与える
大規模言語モデルに対して指示を出すとき。「何をどうするのか」という点を意識する。 より分かりやすい指示を与えることが大切。 少し冗長だと思う表現であるとしても、より分かりやすく指示することで精度が向上する。 特にパラメータ数の少ないモデルでは顕著。
否定するよりも肯定のヒントを与える方が良い
「xxしないでください」と書くよりも、「xxしてください」の方が、より良い結果を出力できる。
性能を改善するキーフレーズを加える
「深呼吸して」「ステップごとに考えて」などのキーフレーズを加えることで、性能が改善することがある。
ペルソナを設定しよう
名前、年齢、性別、年収、職業などを設定して、その人物に対してインタビューすることで、マーケティングに活用することができる。 専門家になってもらうことで、特定分野の質問に的確に答えることができるようになる。
複雑なタスクは分割しよう
人間側でタスクを分割しても良いし、大規模言語モデル自身に複雑なタスクを分割するように依頼することもできる。
テンプレートを使った10倍役立つプロンプト集
プロフィールと履歴書の生成プロンプト
大規模言語モデルを使うことでよりよい履歴書を作ろう
「書類作成の手間を省くため」という側面よりも、「よりよい書類を作成するため」という側面が大きい。
命名プロンプト - ペットの名前からブログのタイトルまで
まとめ
何の予備知識もなしに「xxxの名前を考えて」と書いただけでは、一般的な名前しか出力されないという点が重要。 良い命名を行うためには、固有ドメイン知識(専門分野に関する知識)や命名の目的を意識する点がある。
アイディア発想法を駆使したアイデア生成プロンプト
アイデア発想フレームワーク
大規模言語モデルは、こうしたフレームワークを熟知しており、それぞれのアイデア発想法を利用したプロンプトを作ることができる。
アイデア発想法のフレームワークを使わない場合
一般的なプロンプトを与えると、一般的なアイデアしか出力されない。
ペルソナ法を使ったアイデア発想法
- ペルソナ設定
- ペルソナのニーズの特定
- ソリューションのアイデア出し
大規模言語モデルとこのペルソナ法は、実に相性が良い手法です。 大規模言語モデルは、膨大なテキストを学習していることから、様々なアイデアが発想できますが、何の情報も与えられない場合には、 一般的なアイデアしか出力できません。 しかし、ペルソナを想定して、情報を限定することで、よりユーザにマッチした具体的なアイデアや解決策を生成することが可能になる。
業務自動化1 - Excel/ファイル一括処理プロンプト
VBAマクロを使う方法ならExcel単体でok
VBAはある一部のプログラマーから「時代遅れ」で「扱いにくい」と評されることもある。 しかし、何十年もの間、時代の荒波を乗り越えExcelに搭載されている素晴らしいプログラミング言語です。
業務自動化2 - ブラウザ制御/スクレイピング生成プロンプト
ChatGPTがSeleniumの新しいバージョンを知らない問題
ChatGPTが使っているバージョンを尋ね、そのバージョンをインストールすると良い。
プロンプトエンジニアリングの信頼できる資料
OpenAIが公開しているプロンプトエンジニアリングの指南
- OpenAI > Prompt engineering https://platform.openai.com/docs/guides/prompt-engineering
dair-aiのプロンプトエンジニアリングガイド
- GitHub > dair-ai > Prompt Engineering Guide https://www.promptingguide.ai/jp
Google AIのプロンプト設計戦略について
- Google AI > プロンプト設計戦略 https://ai.google.dev/gemini-api/docs/prompting-strategies?hl=ja
Web APIとオープンLLMの使い方
OpenAI ChatGPT APIの使い方
ChatGPTをAPI経由で使うメリット
- 既存のシステムやアプリケーションに、ChatGPTを組み込むことが可能
- あらかじめ用意してあったプロンプトを組み合わせることが可能
ChatGPT APIを使って会話してみよう
chat.completions.creawteメソッドを連続で呼び出しても、連続した会話とは認識されない。
連続した会話として認識させたい場合には、それまでの対話を引数messagesにリスト型で与える必要がある。
chat.completions.createメソッドに与えるmessagesには会話の履歴を与えることになっている。
その際、ユーザの発言なのか、ChatGPTの応答なのかを区別する必要があり、ユーザであれば、roleプロパティに「user」を指定し、
ChatGPTの応答には「assistant」を与える必要がある。
ChatGPTの振る舞いをしていするために、会話の始めに、roleに「system」を指定することができる。
Azure OpenAIサービスを利用しよう
本家のOpenAI platformよりも、Azureから使う方がレスポンスが早くて安定して使うことができる。
Azure OpenAI Studioでモデルをデプロイしよう
APIから利用するモデルを有効にするためにデプロイする必要がある。 この作業は「Azure OpenAI Studio」で行う必要がある。
Azure OpenAIを利用したプログラムを作る
Azure OpenAIを使う場合も、Pythonパッケージの「openai」が必要になる。
AGIを目指した高度なプロンプトエンジニアリング
API板のMAGIシステム - MAGI ToT
MAGI ToTで今日のランチを決めよう
ユーザプロンプトよりも、システムプロンプトに与える指示の方が、より強い影響力を持つことになっている。
グラウディング - 検索など外部リソースなどの利用
グラウディングについて
大規模言語モデルの学習データを最新に保つのは非常に難しい。 この問題を補うために、検索エンジンなどの外部リソースと大規模言語モデルを組み合わせる手法が考案された。 これが「グラウディング(grounding)」。
グラウディングによって大規模言語モデルの欠点を補完できる
ハルシネーションを防ぐ効果も期待できる。
大規模言語モデルに外部ツールを与えよう
ユーザの質問に対して、大規模言語モデルが知らない場合に、言語モデル自身に外部ツールを選んでもらうようにする。
ベクトルデータベースとの連携
大規模言語モデルとベクトルデータベースを組み合わせよう
Embeddingについて
ベクトルDBが従来型のDBと異なるのは、機械学習モデルによって生成されたEmbedding(特徴ベクトル)を利用して検索を行うことができる。 ベクトルDBを利用すると、DBに蓄えたデータから質問に関連する資料のみを抽出するだけでなく、長文の文章から要約する際に必要となる情報のみを取り出すことができる。
Embeddingとベクトルデータベースについて
文章をEmbeddingに変換するプログラム
Embeddingというのは、直訳すると「埋め込み」となりますが、これはテキストの構成要素を元にして空間におけるベクトルに変換したものです。 類似する文章ほど近いベクトルを返す。
ベクトルデータベースを使った長文の要約
長文をいくつかのチャンク(文章を一定の文字数に分割したもの)に分けて、ベクトルデータベースに挿入する。
ベクトルデータベースを使わない長文の要約
長文の一定のチャンクに分割し、それぞれのチャンクを要約する。 そしれ、それをさらにチャンクに分割し、それぞれのチャンクを要約する。 これを繰り返し、一定の文字数になるまで繰り返す。 この要約は、「Map Reduce(分けてまとめる)」と呼ばれる要約アルゴリズムです。